

Internationalization workflow
Adapting the LEVANTE tasks to a new language is a big job! The internationalization process is a collaboration between the LEVANTE Data Coordinating Center (DCC) at Stanford and sites using LEVANTE in a new language. While we at the DCC provide substantial support, sites are responsible for extensively reviewing the text and audio at multiple stages. As we may not have expertise in your language or culture, sites are responsible for confirming the final content of adaptations.
Text is stored in Crowdin, a platform designed for collaboration with translators.
General workflow
For most tasks, the general workflow is as follows:
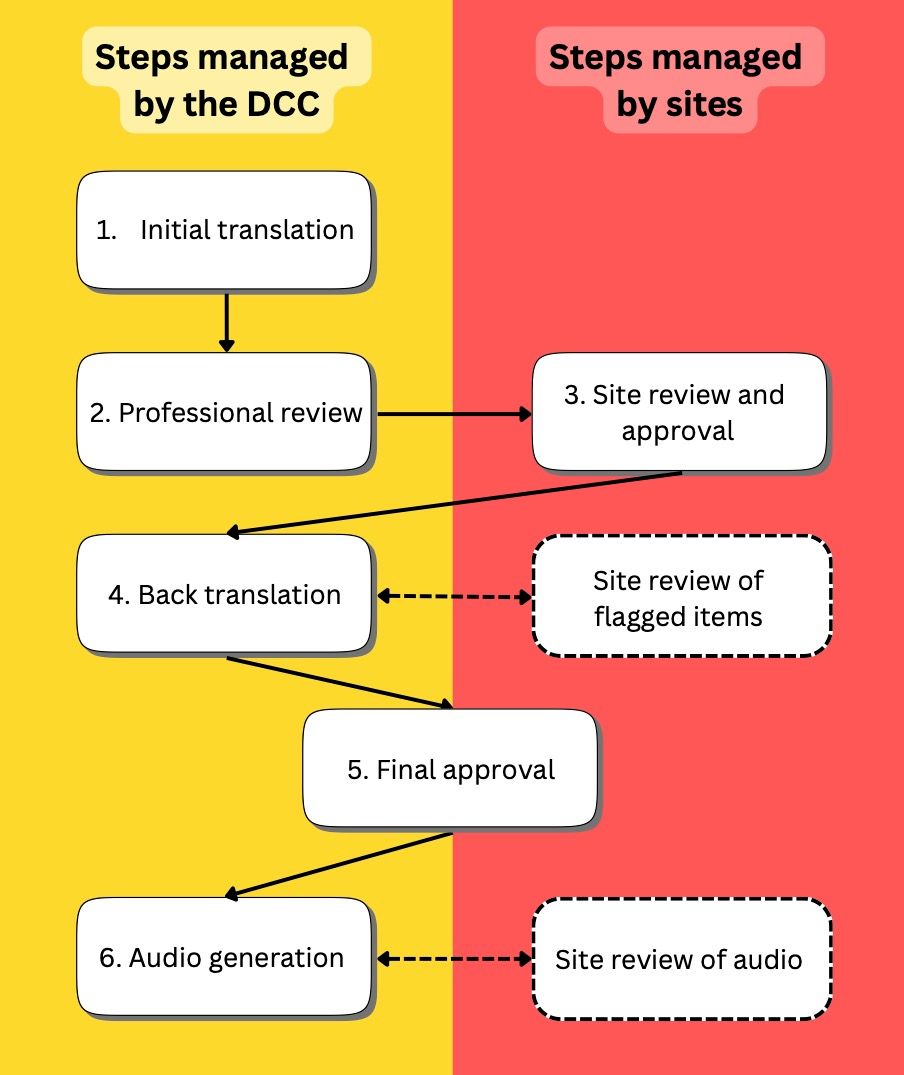
- Initial translation. We use AI to create initial translations of new languages (see below for information on new dialects of existing translations).
- Professional review. We contract a professional translator to review initial translations.
- Site review and approval. Researchers at collaborating sites review and adjust translations alongside the original English tasks (to provide context and imagery).
- Back translation. We back-translate text into English using AI and compare it against the original text to identify deviations in meaning and item intent. Significant deviations are discussed with sites and translations are adjusted as needed.
- Final approval. At this step, both the site and the DCC are satisfied with the translations. We generally expect no further edits to the text after this step. Any requests to edit text or audio after this point require justification related to scientific integrity of a task which arises e.g., during piloting.
- Audio generation. We generate new voice audio using AI and clips are reviewed and finalized in collaboration with sites (see Audio Generation).
When generating a new dialect of an already-translated language, the first two steps may be skipped. Instead, the approved, already-translated language may be sent directly to sites for review and necessary adjustments appropriate to the new dialect. If more than one dialect of a language is already in use, sites can choose which dialect they would like to use as their starting point.
Figure 1. Data Coordinating Center (DCC) and site responsibilities during the internationalization process for non-language tasks
If sites and the DCC hold differing views on measure translation or adaptation, we will arrange a meeting to reach a shared decision. In the rare case when consensus cannot be achieved, the topic will be referred to the LEVANTE project’s independent scientific steering committee for resolution.
Language and social cognition tasks
LEVANTE language tasks include Vocabulary, Sentence Understanding, Language Sounds, Word Reading, and Sentence Reading; the social cognition task is Stories (see Direct Child Measures). Internationalization for these tasks is more challenging and may require a number of additional steps, including:
- Item development
- Review of all items by a psychology researcher with expertise in the relevant culture, language, and developmental sample (See Task-specific considerations)
- Pruning and adding items in consultation with highly specialized experts
- Grammar items for the Sentence Understanding task requires expertise in syntactic acquisition for the relevant language
- Phoneme awareness items on the Language Sounds task (for alphabetic languages) requires expertise in phonology and reading development for the relevant language
- Creating new illustrations as needed
- Task validation
- Differential item function checks with existing task versions (i.e., across languages and samples)
- Evaluating within-site reliability
- Evaluating configural invariance with other language tasks
- Potential validation with other measures, e.g. standardized tasks
- Item bank norming
- Collecting enough data on new items to create and deploy a computerized adaptive test with language-specific parameters
The challenges involved in this work will vary by language/dialect and culture. In general, adapting to language tasks to those with more similar grammar and morphology to already-supported languages (see Internationalization Status) is easier.